Você verá nesta página um tutorial introdutório sobre Redes Neurais Artificiais, em especial sobre as Redes Multi Layer Perceptron treinadas com BackPropagation
![]() Perceptron
multi-camadas (MLP)
Perceptron
multi-camadas (MLP)
Redes Neurais Artificiais são técnicas computacionais que apresentam
um modelo matemático inspirado na estrutura neural de organismos inteligentes
e que adquirem conhecimento através da experiência. Uma grande
rede neural artificial pode ter centenas ou milhares de unidades de processamento;
já o cérebro de um mamífero pode ter muitos bilhões
de neurônios.
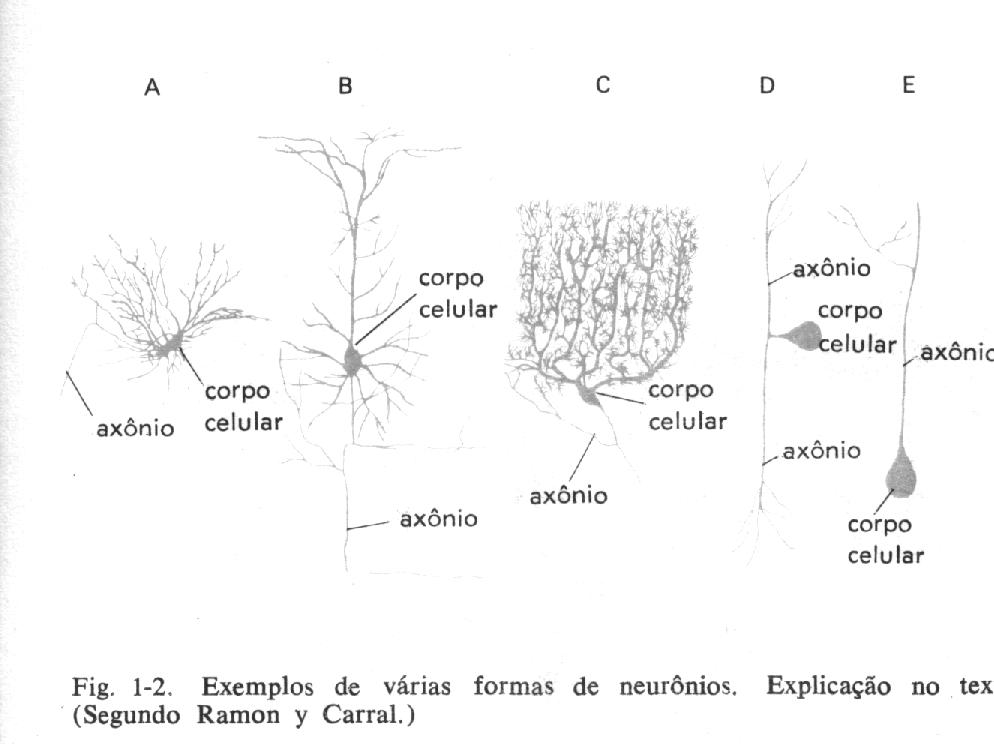
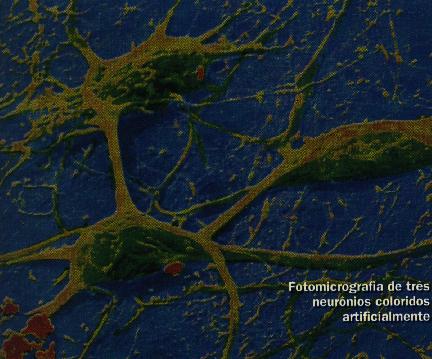
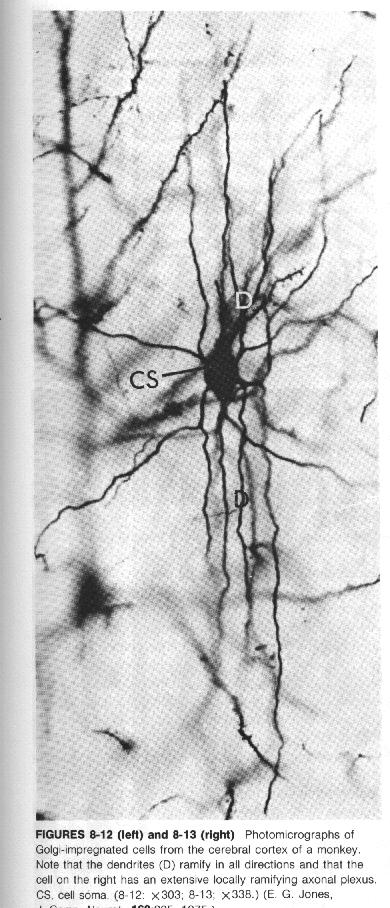
O sistema nervoso é formado por um conjunto extremamente complexo de células, os neurônios. Eles têm um papel essencial na determinação do funcionamento e comportamento do corpo humano e do raciocínio. Os neurônios são formados pelos dendritos, que são um conjunto de terminais de entrada, pelo corpo central, e pelos axônios que são longos terminais de saída.
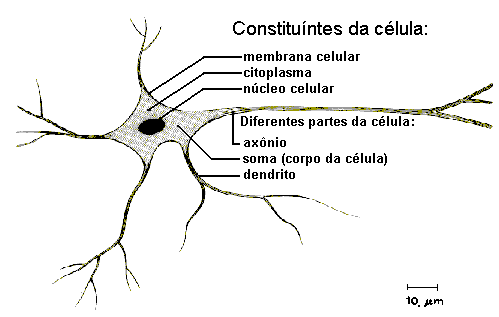
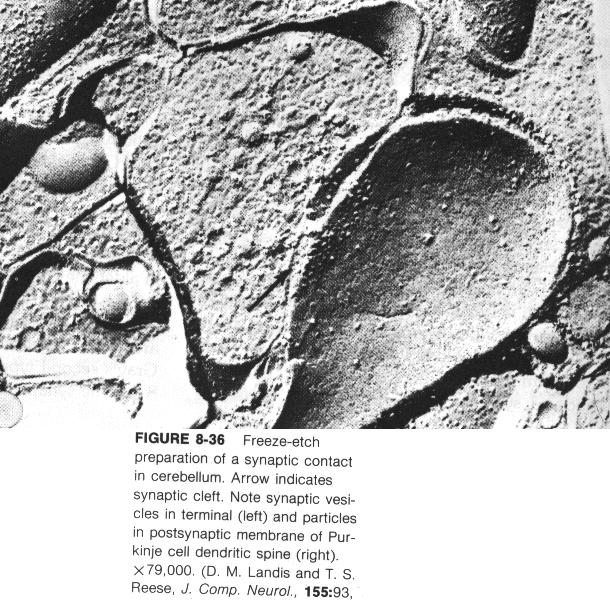
Os neurônios se comunicam através de sinapses. Sinapse é a região onde dois neurônios entram em contato e através da qual os impulsos nervosos são transmitidos entre eles. Os impulsos recebidos por um neurônio A, em um determinado momento, são processados, e atingindo um dado limiar de ação, o neurônio A dispara, produzindo uma substância neurotransmissora que flui do corpo celular para o axônio, que pode estar conectado a um dendrito de um outro neurônio B. O neurotransmissor pode diminuir ou aumentar a polaridade da membrana pós-sináptica, inibindo ou excitando a geração dos pulsos no neurônio B. Este processo depende de vários fatores, como a geometria da sinapse e o tipo de neurotransmissor.
Em média, cada neurônio forma entre mil e dez mil sinapses. O cérebro humano possui cerca de 10 E11 neurônios, e o número de sinapses é de mais de 10 E14, possibilitando a formação de redes muito complexa.
Um histórico resumido sobre Redes Neurais Artificiais deve começar
por três das mais importantes publicações iniciais, desenvolvidas
por: McCulloch e Pitts (1943), Hebb (1949), e Rosemblatt (1958). Estas publicações
introduziram o primeiro modelo de redes neurais simulando máquinas,
o modelo básico de rede de auto-organização, e o modelo
Perceptron de aprendizado supervisionado, respectivamente.
Alguns históricos sobre a área costumam pular os anos 60 e 70 e apontar um reínicio da área com a publicação dos trabalhos de Hopfield (1982) relatando a utilização de redes simétricas para otimização e de Rumelhart, Hinton e Williams que introduziram o poderoso método Backpropagation.
Entretanto, para se ter um histórico completo, devem ser citados alguns pesquisadores que realizaram, nos anos 60 e 70, importantes trabalhos sobre modelos de redes neurais em visão, memória, controle e auto-organização como: Amari, Anderson, Cooper, Cowan, Fukushima, Grossberg, Kohonen, von der Malsburg, Werbos e Widrow.
Uma rede neural artificial é composta por várias unidades de processamento,
cujo funcionamento é bastante simples. Essas unidades, geralmente são
conectadas por canais de comunicação que estão associados
a determinado peso. As unidades fazem operações apenas sobre seus
dados locais, que são entradas recebidas pelas suas conexões.
O comportamento inteligente de uma Rede Neural Artificial vem das interações
entre as unidades de processamento da rede.
A operação de uma unidade de processamento, proposta por McCullock e Pitts em 1943, pode ser resumida da seguinte maneira:
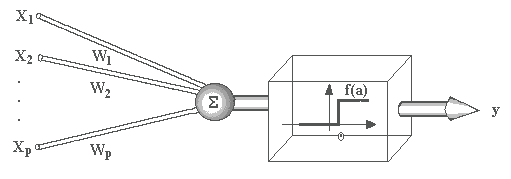
Suponha que tenhamos p sinais de entrada X1, X2, ..., Xp e pesos w1, w2, ..., wp e limitador t; com sinais assumindo valores booleanos (0 ou 1) e pesos valores reais.
Neste modelo, o nível de atividade a é dado por:
a = w1X1 + w2X2 + ... + wpXp
A saída y é dada po
A maioria dos modelos de redes neurais possui alguma regra de treinamento, onde os pesos de suas conexões são ajustados de acordo com os padrões apresentados. Em outras palavras, elas aprendem através de exemplos.
Arquiteturas neurais são tipicamente organizadas em camadas, com unidades que podem estar conectadas às unidades da camada posterior.
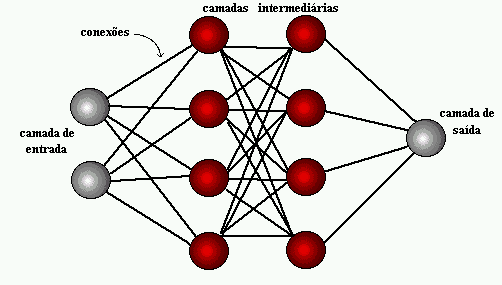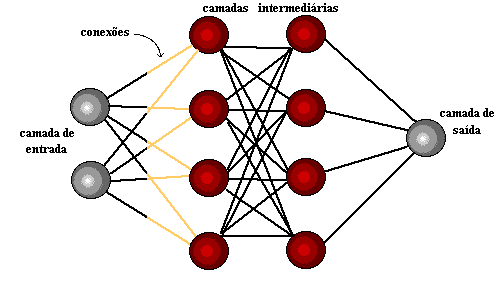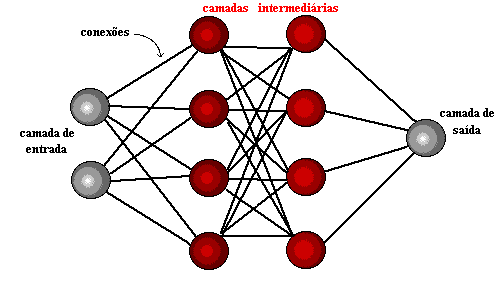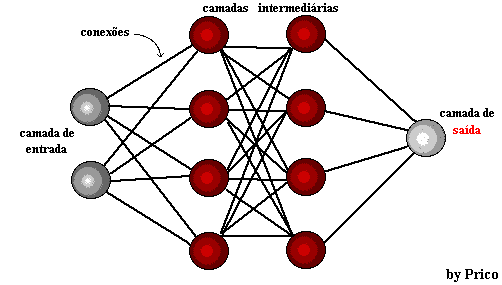
Uma rede neural é especificada, principalmente pela sua topologia, pelas características dos nós e pelas regras de treinamento. A seguir, serão analisados os processos de aprendizado.
A propriedade mais importante das redes neurais é a habilidade de aprender
de seu ambiente e com isso melhorar seu desempenho. Isso é feito através
de um processo iterativo de ajustes aplicado a seus pesos, o treinamento. O
aprendizado ocorre quando a rede neural atinge uma solução generalizada
para uma classe de problemas.
Denomina-se algoritmo de aprendizado a um conjunto de regras bem definidas para a solução de um problema de aprendizado. Existem muitos tipos de algoritmos de aprendizado específicos para determinados modelos de redes neurais, estes algoritmos diferem entre si principalmente pelo modo como os pesos são modificados.
Outro fator importante é a maneira pela qual uma rede neural se relaciona com o ambiente. Nesse contexto existem os seguintes paradigmas de aprendizado:
Denomina-se ciclo uma apresentação de todos os N pares (entrada e saída) do conjunto de treinamento no processo de aprendizado. A correção dos pesos num ciclo pode ser executado de dois modos:
1) Modo Padrão: A correção dos pesos acontece a cada apresentação à rede de um exemplo do conjunto de treinamento. Cada correção de pesos baseia-se somente no erro do exemplo apresentado naquela iteração. Assim, em cada ciclo ocorrem N correções.
2) Modo Batch: Apenas uma correção é feita por ciclo. Todos os exemplos do conjunto de treinamento são apresentados à rede, seu erro médio é calculado e a partir deste erro fazem-se as correções dos pesos.
O treinamento supervisionado do modelo de rede Perceptron, consiste em ajustar
os pesos e os thresholds de suas unidades para que a classificação
desejada seja obtida. Para a adaptação do threshold juntamente
com os pesos podemos considerá-lo como sendo o peso associado a uma conexão,
cuja entrada é sempre igual à -1 e adaptar o peso relativo a essa
entrada.
Quando um padrão é inicialmente apresentado à rede, ela produz uma saída. Após medir a distância entre a resposta atual e a desejada, são realizados os ajustes apropriados nos pesos das conexões de modo a reduzir esta distância.Este procedimento é conhecido como Regra Delta.
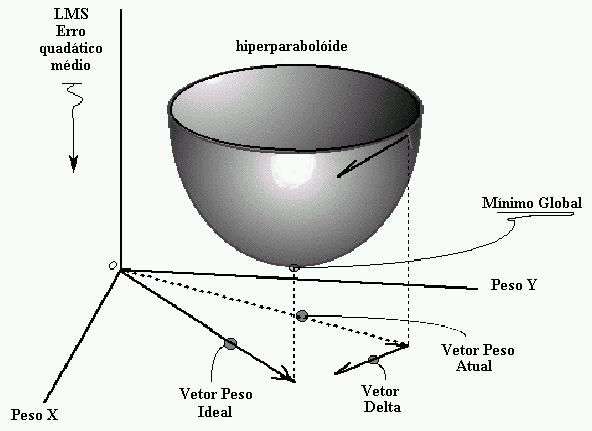
Deste modo, temos o seguinte esquema de treinamento.
Iniciar todas as conexões com pesos aleatórios;
Repita até que o erro E seja satisfatoriamente pequeno (E = e)
Para cada par de treinamento (X,d), faça:
Calcular a resposta obtida O;
Se o erro não for satisfatoriamente pequeno E > e, então:
Atualizar pesos: Wnovo := W anterior + neta E X
Onde:
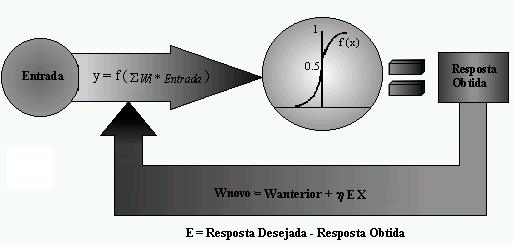
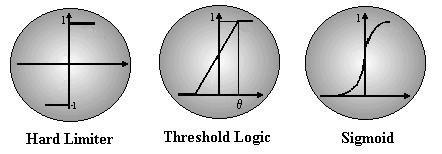
As respostas geradas pelas unidades são calculadas através de uma função de ativação. Existem vários tipos de funções de ativação, as mais comuns são: Hard Limiter, Threshold Logic e Sigmoid.
Links para páginas sobre Redes Neurais Artificiais.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}